YDB overview
YDB is a horizontally scalable distributed fault-tolerant DBMS. YDB is designed for high performance with a typical server being capable of handling tens of thousands of queries per second. The system is designed to handle hundreds of petabytes of data. YDB can operate in single data center and geo-distributed (cross data center) modes on a cluster of thousands of servers.
YDB provides:
- Strict consistency which can be relaxed to increase performance.
- Support for queries written in YQL (an SQL dialect for working with big data).
- Automatic data replication.
- High availability with automatic failover in case a server, rack, or availability zone goes offline.
- Automatic data partitioning as data or load grows.
To interact with YDB, you can use the YDB CLI and SDK fo C++, C#, Go, Java, Node.js, PHP, Python, and Rust.
YDB supports a relational data model and manages tables with a predefined schema. To make it easier to organize tables, directories can be created like in the file system. In addition to tables, YDB supports topics as an entity for storing unstructured messages and delivering them to multiple subscribers.
Database commands are mainly written in YQL, an SQL dialect. This gives the user a powerful and already familiar way to interact with the database.
YDB supports high-performance distributed ACID transactions that may affect multiple records in different tables. It provides the serializable isolation level, which is the strictest transaction isolation. You can also reduce the level of isolation to raise performance.
YDB natively supports different processing options, such as OLTP and OLAP. The current version offers limited analytical query support. This is why we can say that YDB is currently an OLTP database.
YDB is an open-source system. The YDB source code is available under Apache License 2.0. Client applications interact with YDB based on gRPC that has an open specification. It allows implementing an SDK for any programming language.
Use cases
YDB can be used as an alternative solution in the following cases:
- When using NoSQL systems, if strong data consistency is required.
- When using NoSQL systems, if you need to make transactional updates to data stored in different rows of one or more tables.
- In systems that need to process and store large amounts of data and allow for virtually unlimited horizontal scalability (using industrial clusters of 5000+ nodes, processing millions of RPS, and storing petabytes of data).
- In low-load systems, when supporting a separate DB instance would be a waste of money (consider using YDB in serverless mode instead).
- In systems with unpredictable or seasonally fluctuating load (you can add/reduce computing resources on request and/or in serverless mode).
- In high-load systems that shard load across relational DB instances.
- When developing a new product with no reliable load forecast or with an expected high load beyond the capabilities of conventional relational databases.
How it works?
Fully explaining how YDB works in detail takes quite a while. Below you can review several key highlights and then continue exploring documentation to learn more.
YDB architecture
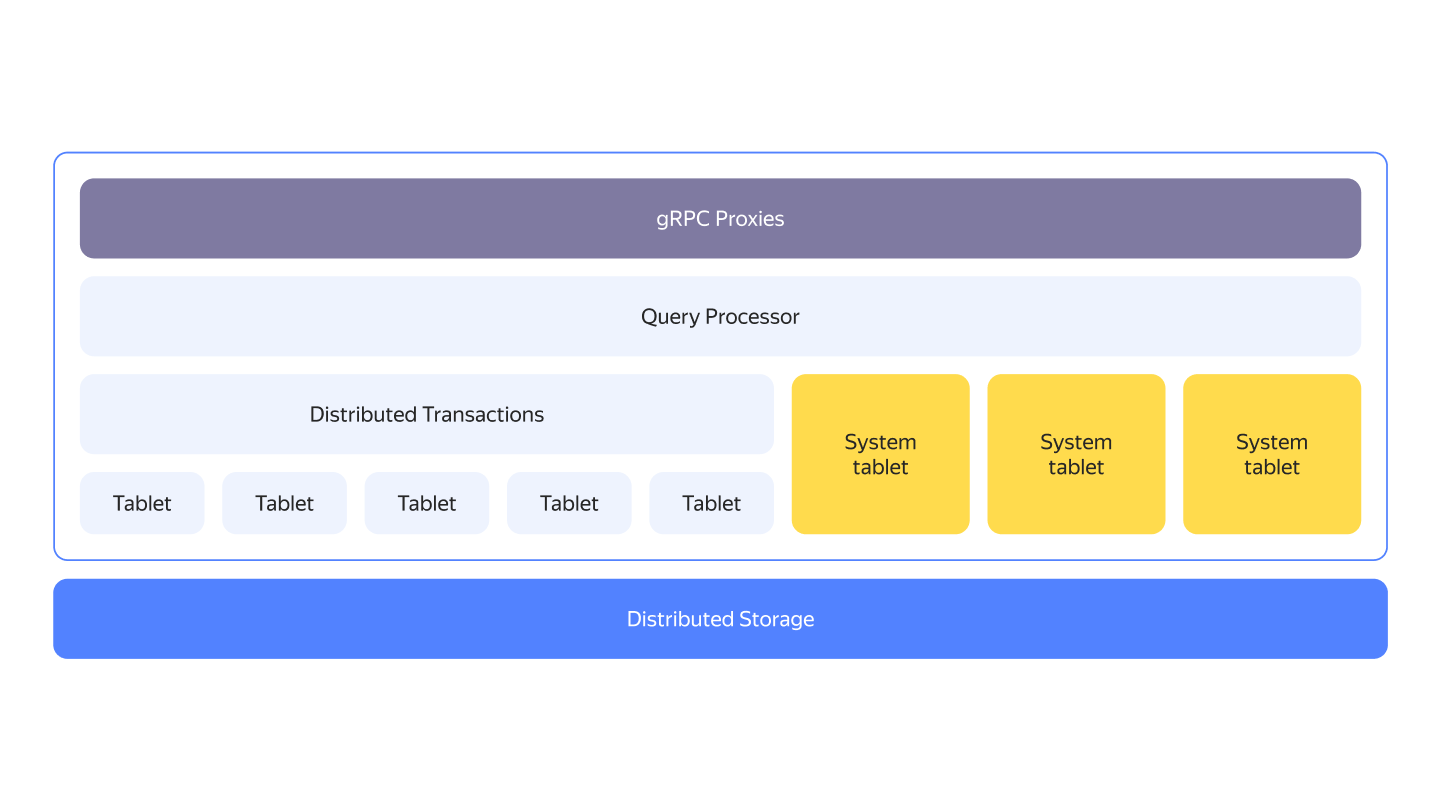
YDB clusters typically run on commodity hardware with shared-nothing architecture. If you look at YDB from a bird's eye view, you'll see a layered architecture. The compute and storage layers are disaggregated, they can either run on separate sets of nodes or be co-located.
One of the key building blocks of YDB's compute layer is called a tablet. They are stateful logical components implementing various aspects of YDB.
The next level of detail of overall YDB architecture is explained in the YDB cluster documentation section.
Hierarchy
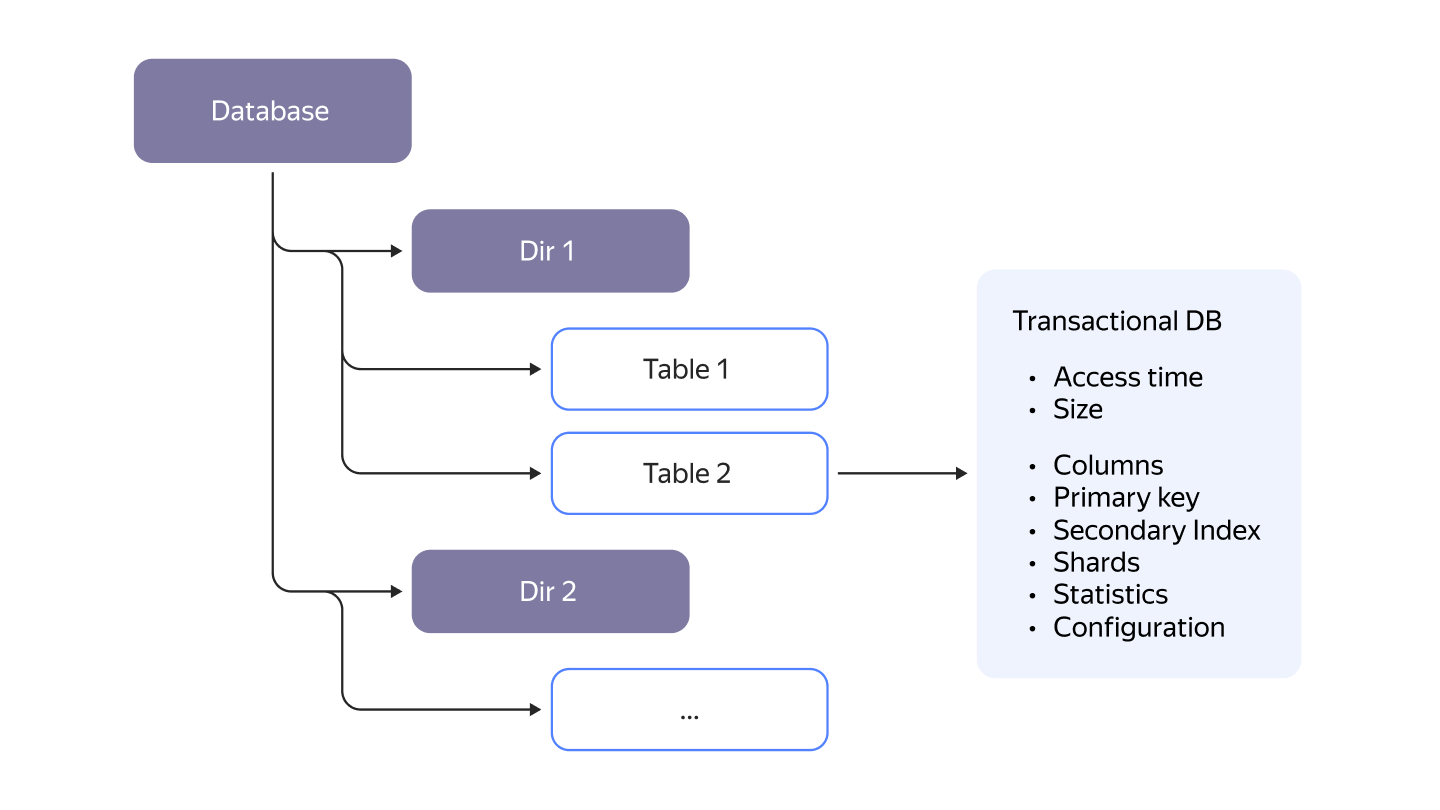
From the user's perspective, everything inside YDB is organized in a hierarchical structure using directories. It can have arbitrary depth depending on how you choose to organize your data and projects. Even though YDB does not have a fixed hierarchy depth like in other SQL implementations, it will still feel familiar as this is exactly how any virtual filesystem looks like.
Table
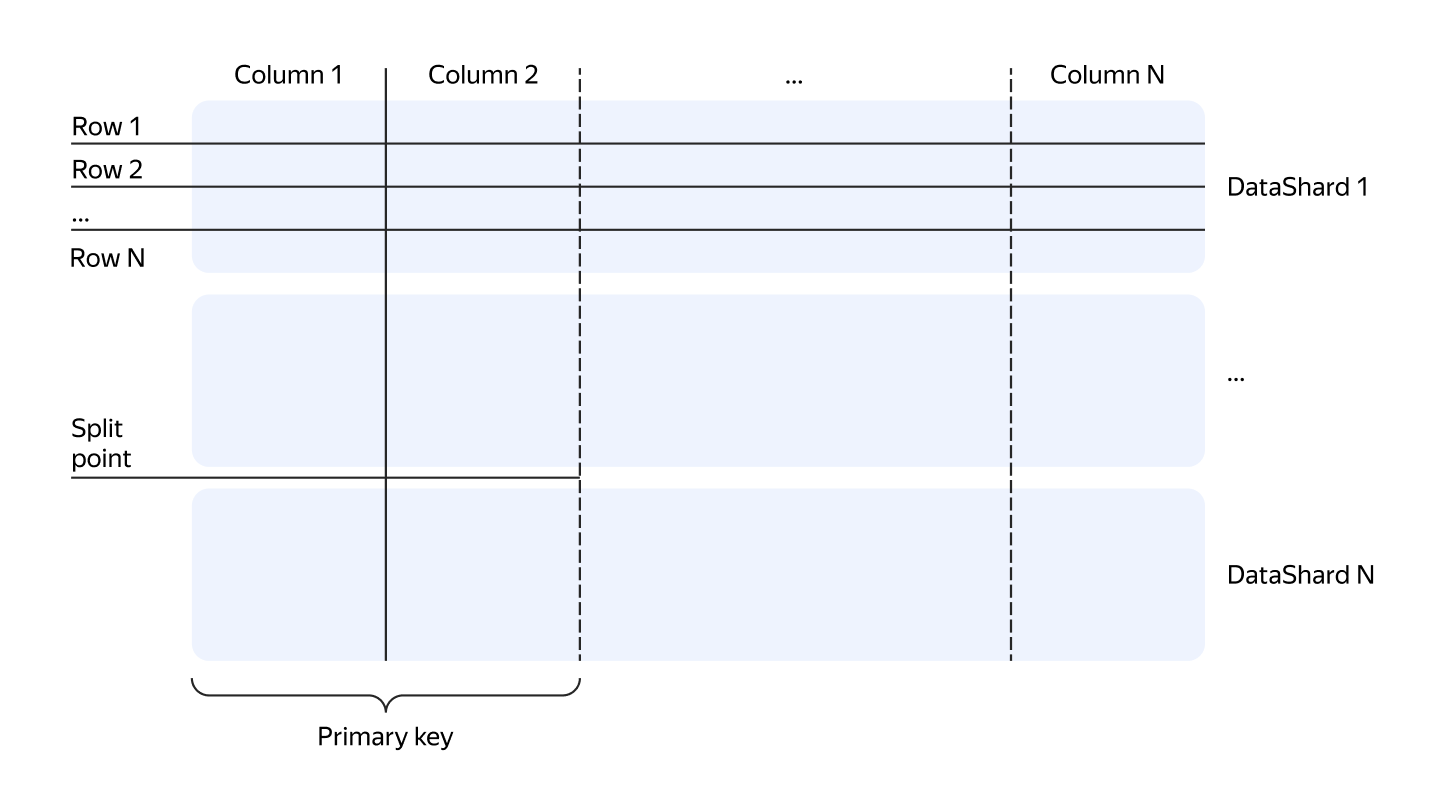
YDB provides users with a well-known abstraction: tables. In YDB tables must contain a primary key, the data is physically sorted by the primary key. Tables are automatically sharded by primary key ranges by size or load. Each primary key range of a table is handled by a specific tablet called data shard.
Split by load

Data shards will automatically split into more ones as the load increases. They automatically merge back to the appropriate number when the peak load goes away.
Split by size
.png)
Data shards also will automatically split when the data size increases. They automatically merge back if enough data will be deleted.
Automatic balancing
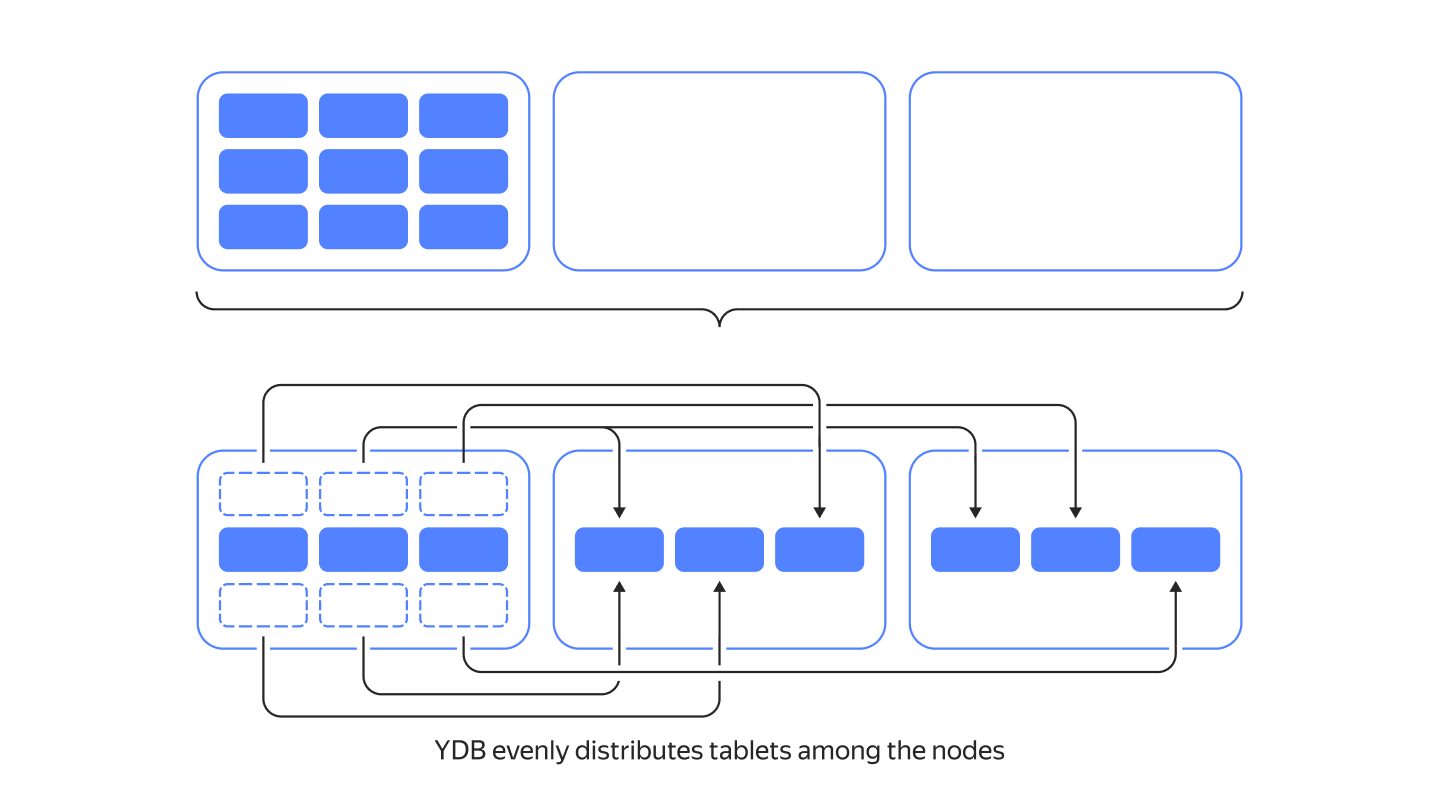
YDB evenly distributes tablets among available nodes. It moves heavily loaded tablets from overloaded nodes. CPU, Memory, and Network metrics are tracked to facilitate this.
Distributed Storage internals
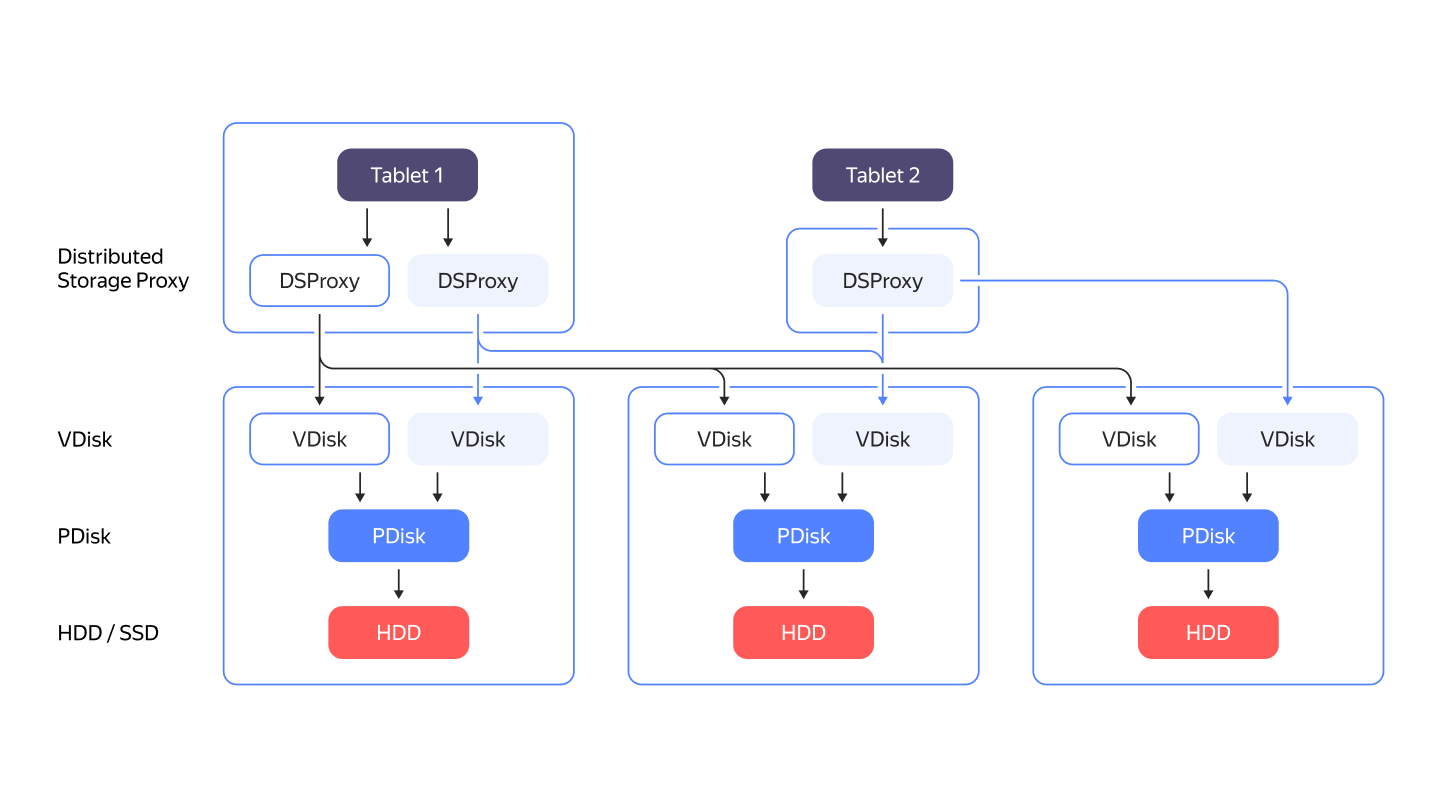
YDB doesn't rely on any third-party filesystem. It stores data by directly working with disk drives as block devices. All major disk kinds are supported: NVMe, SSD, or HDD. The PDisk component is responsible for working with a specific block device. The abstraction layer above PDisk is called VDisk. There is a special component called DSProxy between a tablet and VDisk. DSProxy analyzes disk availability and characteristics and chooses which disks will handle a request and which won't.
Distributed Storage proxy (DSProxy)
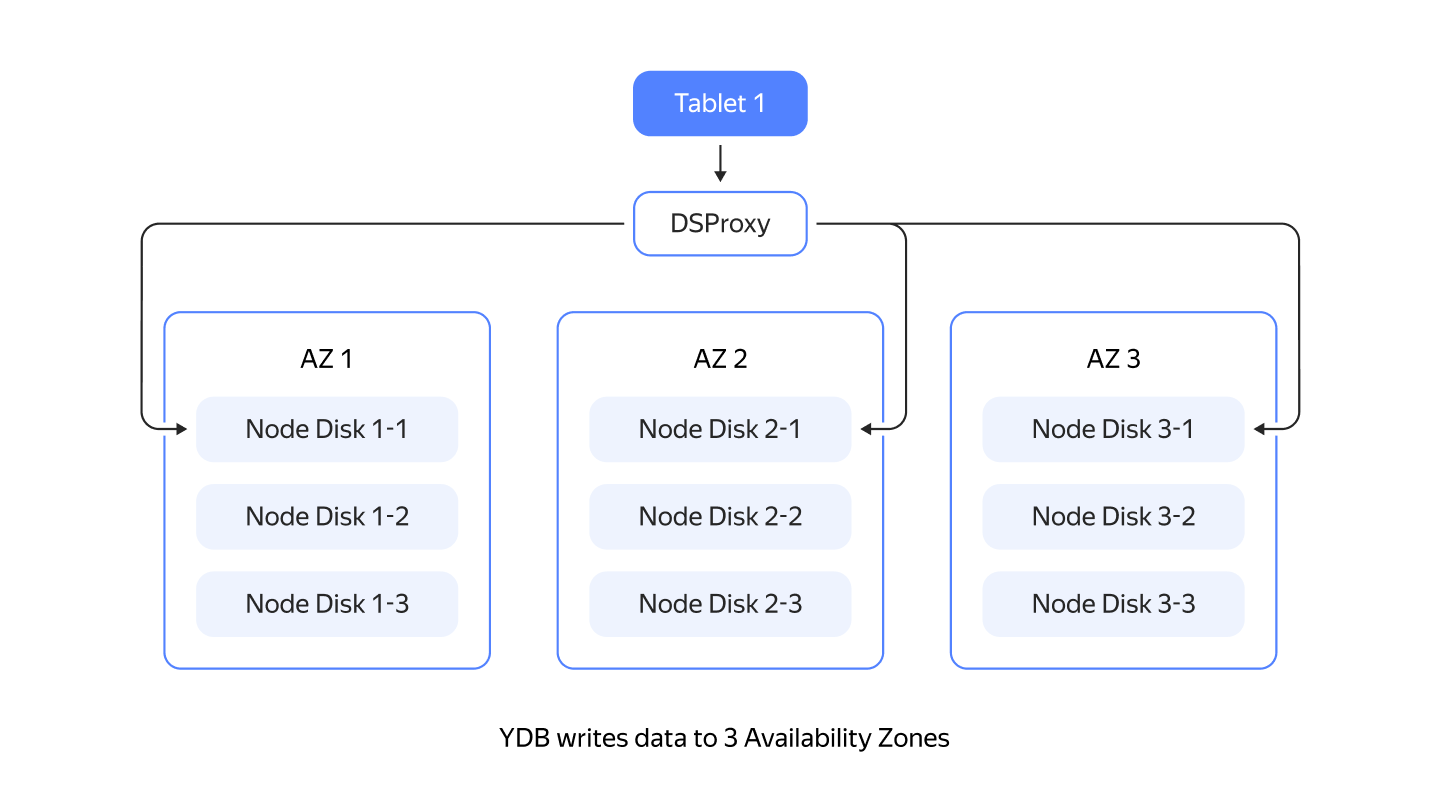
A common fault-tolerant setup of YDB spans 3 datacenters or availability zones (AZ). When YDB writes data to 3 AZ, it doesn’t send requests to obviously bad disks and continues to operate without interruption even if one AZ and a disk in another AZ are lost.
What's next?
If you are interested in more specifics about various aspects of YDB, check out neighboring articles in this documentation section. If you are ready to jump into more practical content, you can continue to the quick start or YQL tutorials.