Как это работает?
Полное объяснение того, как работает YDB, получилось бы слишком объемным. Ниже вы можете ознакомиться с несколькими основными моментами, а затем продолжить изучение документации, чтобы узнать больше.
Архитектура YDB
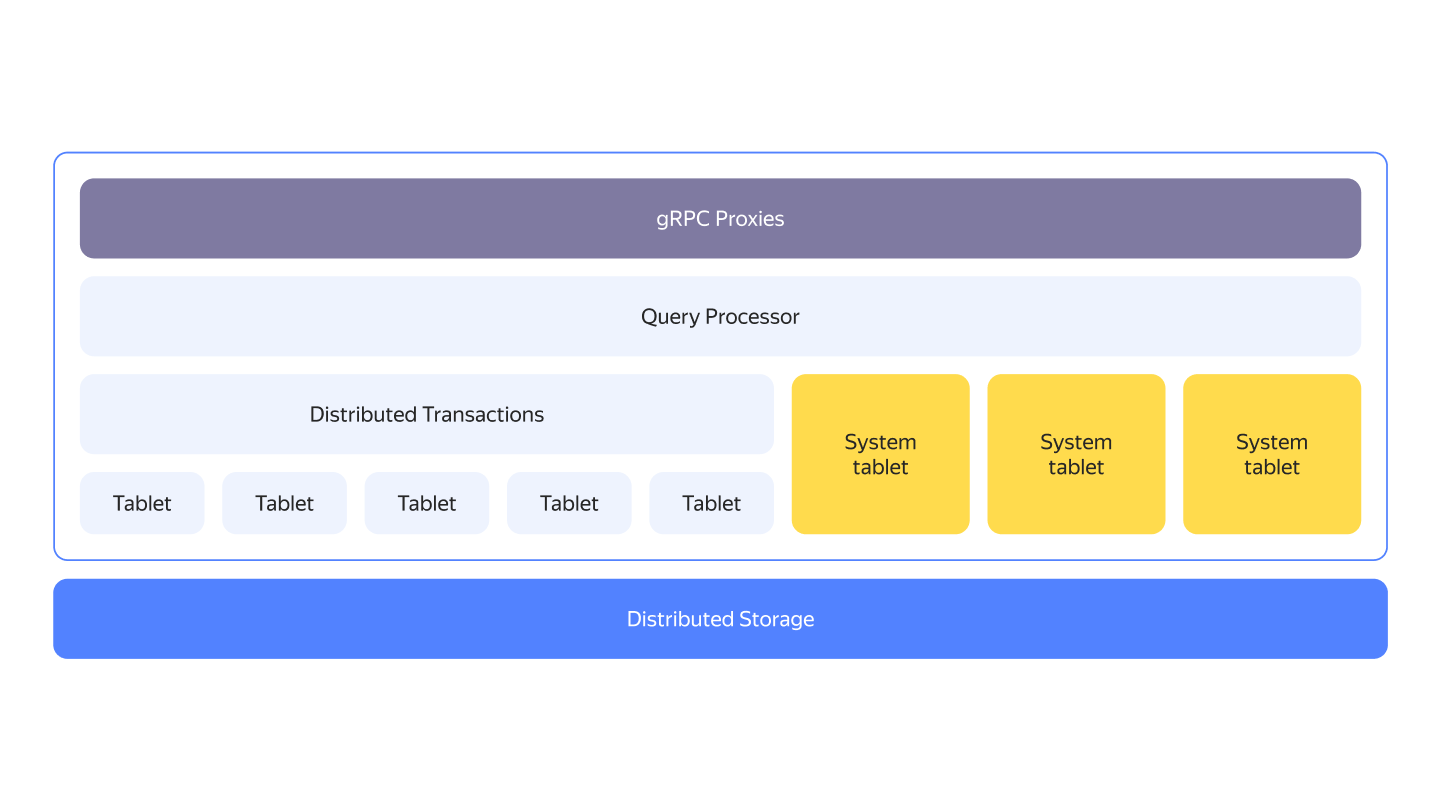
Кластеры YDB обычно работают с shared nothing архитектурой на обычном оборудовании. Уровни вычислений и хранения являются разнёсенными. Они могут работать как на отдельных наборах узлов, так и быть совмещёнными.
Один из ключевых элементов вычислительного слоя YDB называется таблеткой. Они являются логическими компонентами с состоянием, реализующими различные аспекты YDB.
Более подробная общая архитектура YDB объясняется в разделе Общая схема YDB.
Иерархия
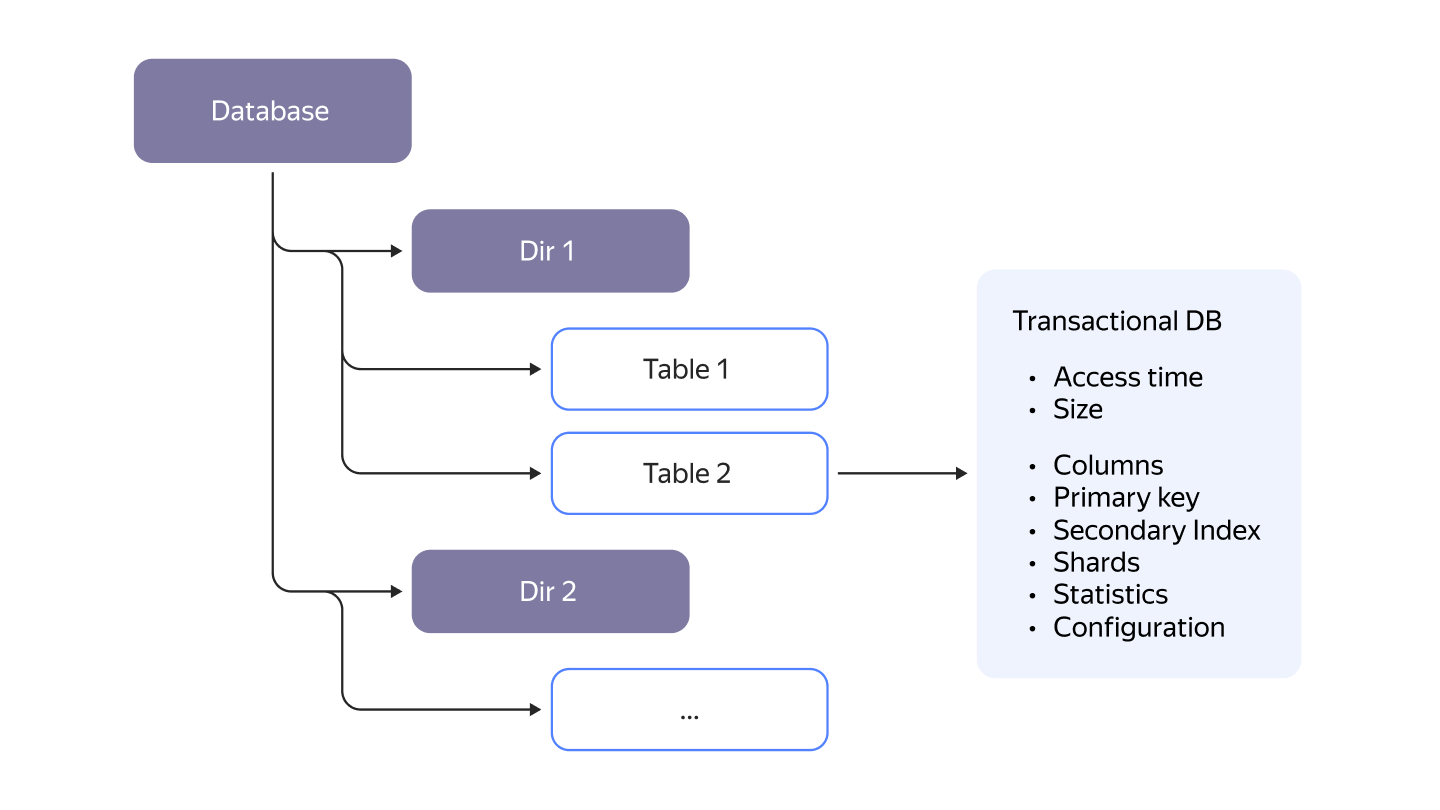
С точки зрения пользователя, всё внутри YDB организовано в иерархической структуре с использованием каталогов. Она может иметь произвольную глубину в зависимости от того, как вы решили организовать свои данные и проекты. Хотя YDB не имеет фиксированной глубины иерархии, как в других реализациях SQL, она все равно будет знакома, поскольку именно так выглядит любая виртуальная файловая система.
Таблица
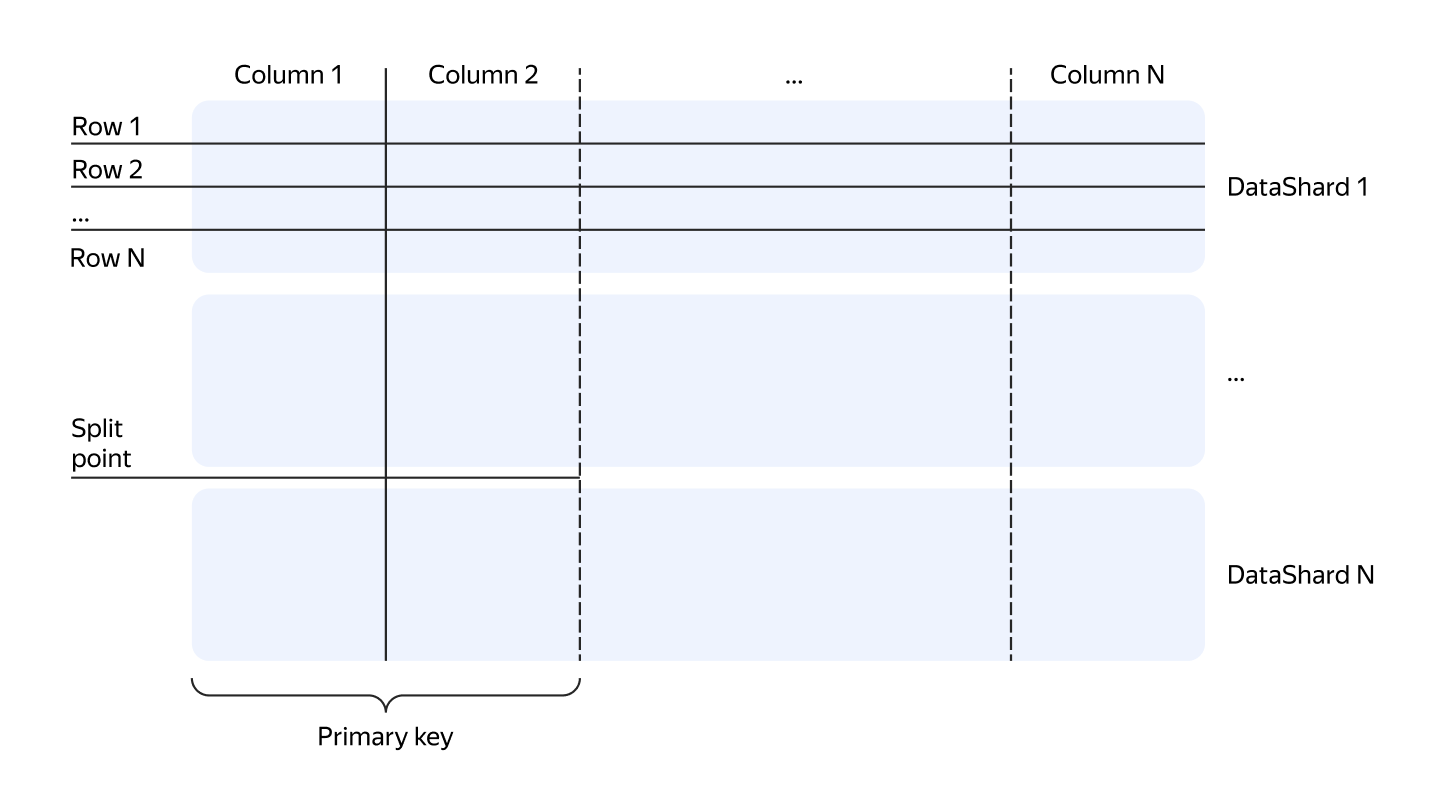
YDB предоставляет пользователям хорошо известную абстракцию — таблицы. В YDB существует два основных типа таблиц:
- Строковые таблицы предназначены для OLTP-нагрузок.
- Колоночные таблицы предназначены для OLAP-нагрузок.
Логически, с точки зрения пользователя, оба вида таблиц выглядят одинаково. Основное отличие между строковыми и колоночными таблицами заключается в способе хранения данных. В строковых таблицах значения всех колонок каждой строки располагаются рядом, а в колоночных таблицах — наоборот, каждая колонка хранится отдельно, и рядом оказываются ячейки, относящиеся к разным строкам.
Независимо от типа таблицы, она должна содержать первичный ключ. В первичном ключе колоночных таблиц можно использовать только колонки с NOT NULL. Данные в таблицах физически сортируются по первичному ключу. Строковые таблицы автоматически партицируются по диапазонам первичных ключей в зависимости от объёма данных, а данные в колоночных таблицах партицируются не по первичному ключу, а по хешу от колонок партицирования. Каждый диапазон первичных ключей таблицы обрабатывается определённой таблеткой, называемой data shard для строчных таблиц и column shard — для колоночных.
Разделение по нагрузке

Data shard автоматически разделяются на большее количество при увеличении нагрузки. Они автоматически объединяются в нужное количество, когда пиковая нагрузка уходит.
Разделение по размеру
.png)
Data shard также автоматически разделяются при увеличении размера данных. Они автоматически сливаются обратно, если достаточное количество данных будет удалено.
Автоматическая балансировка
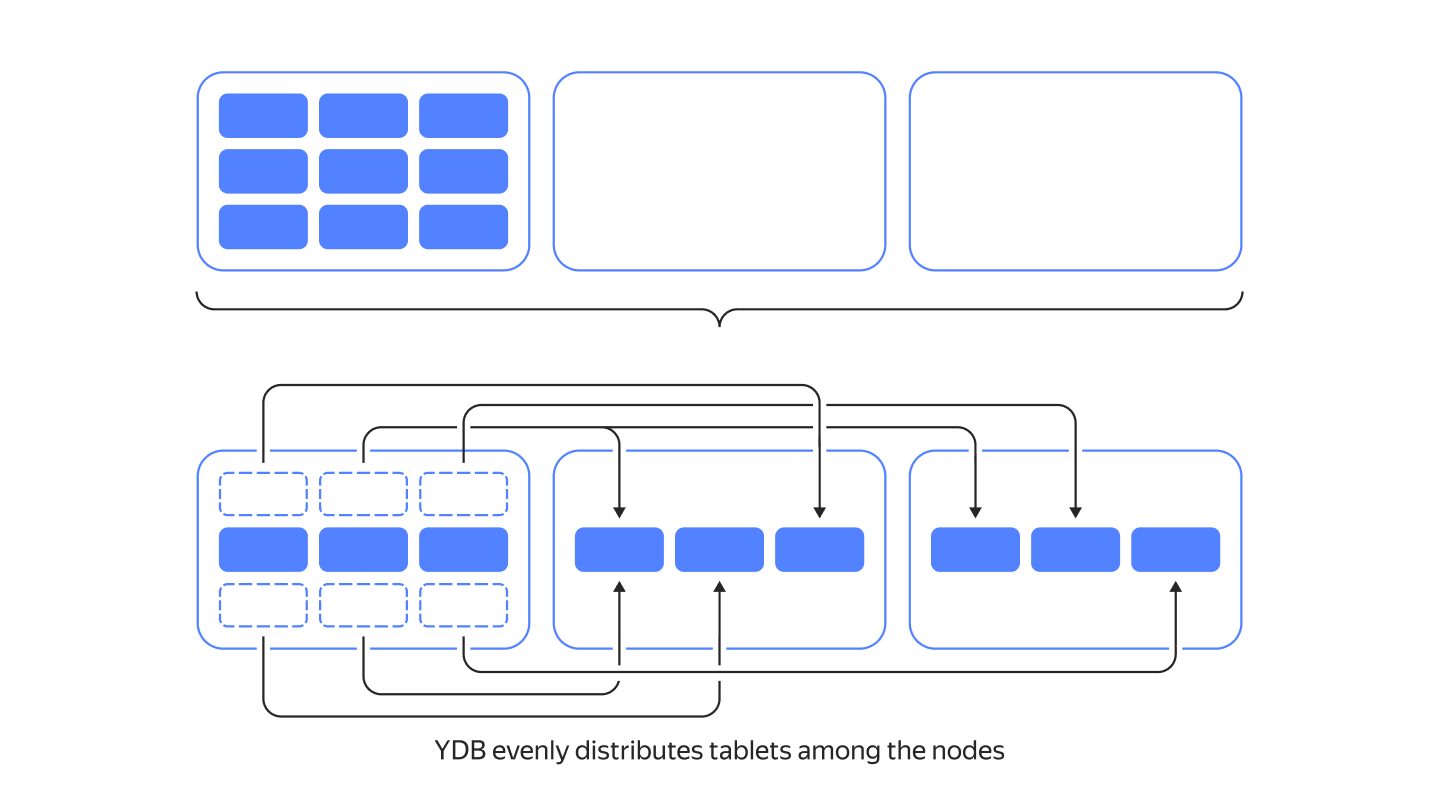
YDB равномерно распределяет таблетки среди доступных узлов. Она перемещает тяжело загруженные таблетки с перегруженных узлов. Метрики CPU, памяти и сети отслеживаются для облегчения этого процесса.
Внутреннее устройство распределенного хранилища
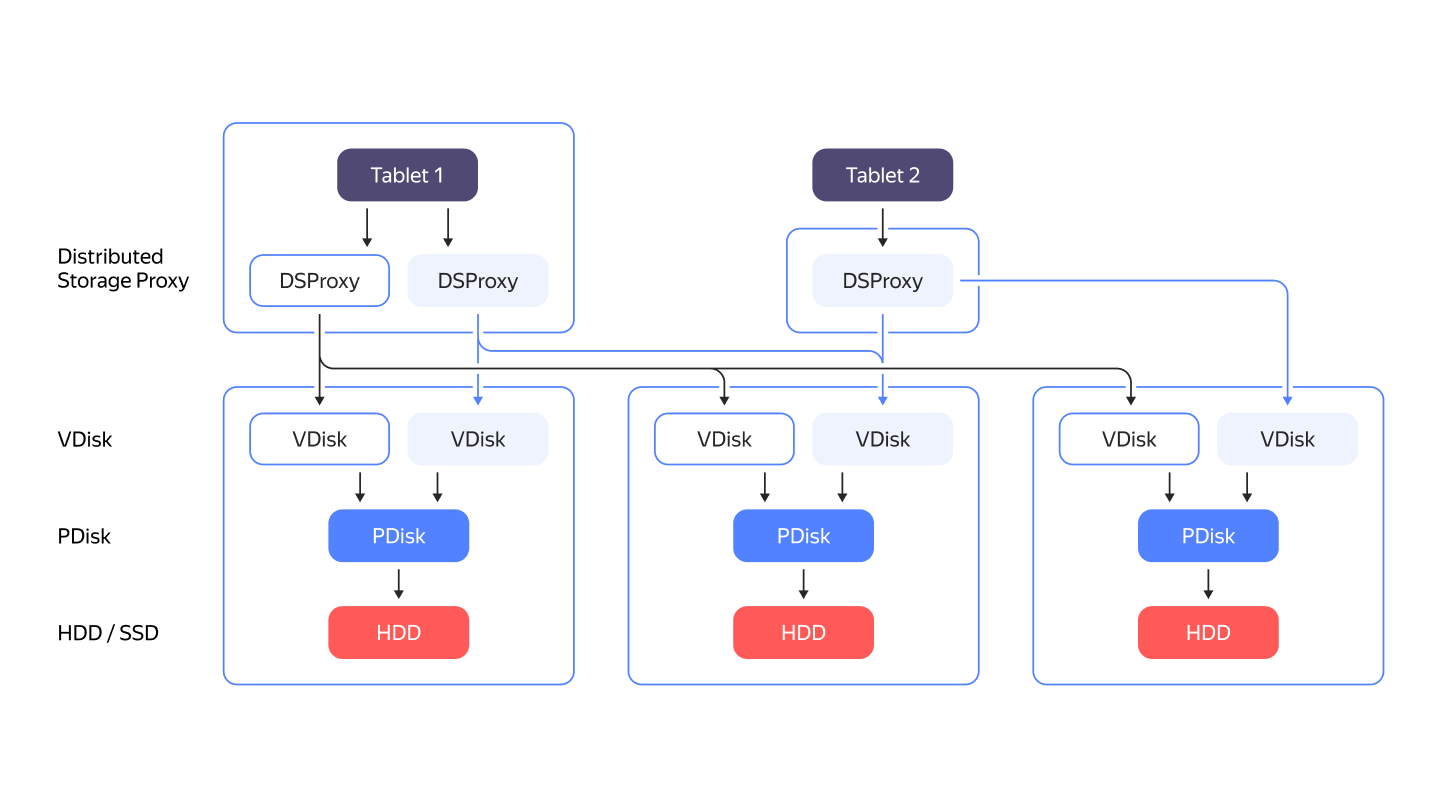
YDB не полагается на сторонние файловые системы. Она хранит данные, работая непосредственно с дисковыми накопителями как блочными устройствами. Поддерживаются все основные типы дисков: NVMe, SSD или HDD. За работу с конкретным блочным устройством отвечает компонент PDisk. Уровень абстракции выше PDisk называется VDisk. Также есть специальный компонент, называемый DSProxy, между таблеткой и VDisk. DSProxy анализирует доступность и характеристики дисков и выбирает, какие диски будут обрабатывать запрос, а какие нет.
Прокси распределенного хранилища (DSProxy)
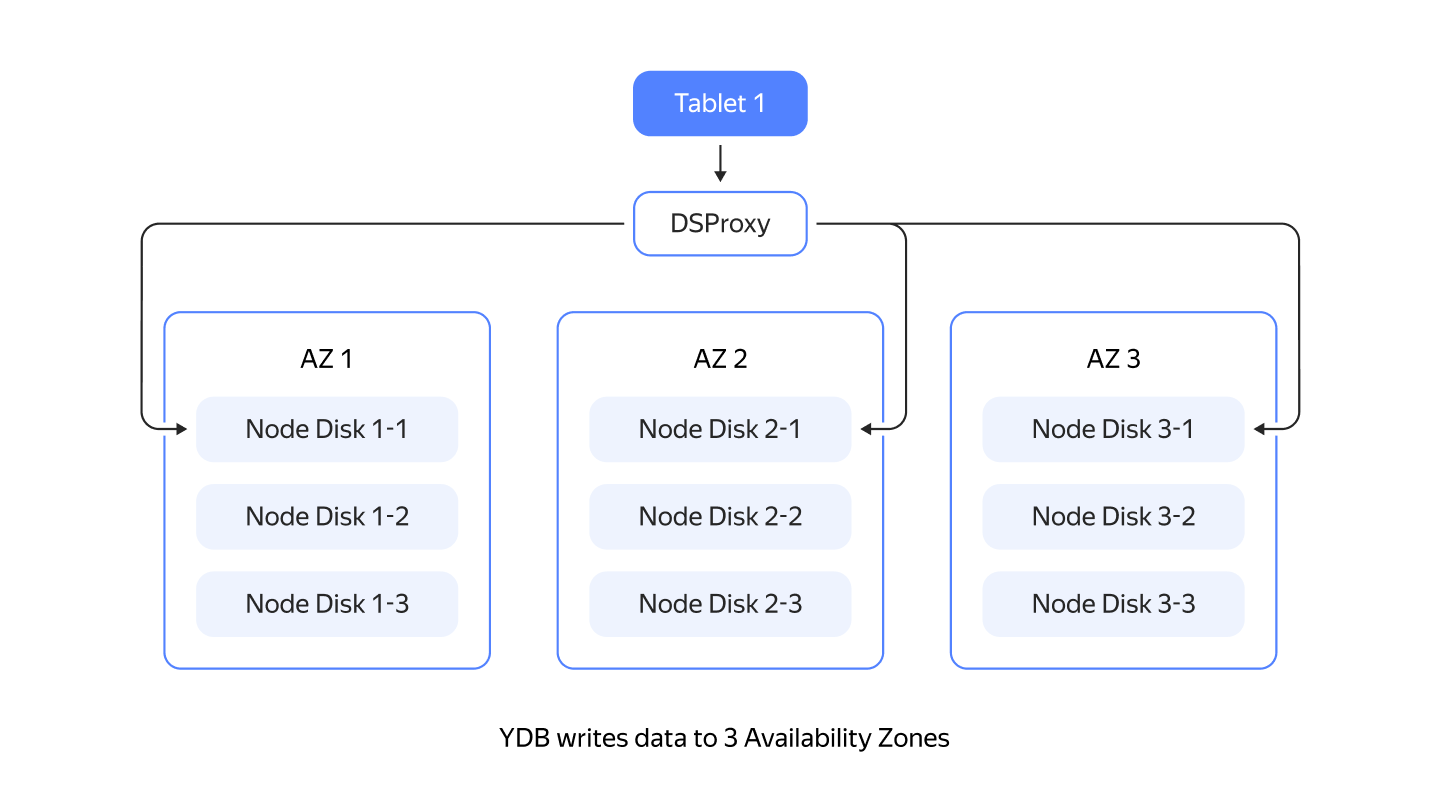
Геораспределенная и отказоустойчивая конфигурация YDB обычно охватывает 3 датацентра или зоны доступности (Availability Zone - AZ). Когда YDB записывает данные на 3 зоны доступности, он не отправляет запросы на явно некорректные диски и продолжает работать без прерываний даже если одна зона доступности и диск в другой зоне доступности потеряны.
Управление ресурсами баз данных
По умолчанию выделяемые каждой базе данных вычислительные ресурсы используются всеми запросами к ней на равных условиях, без каких-либо ограничений. Если требуется разделить ресурсы внутри одной базы данных, то в YDB существуют пулы ресурсов и классификаторы пулов ресурсов. Один из типовых сценариев применения такой функциональности — это разделение контуров онлайн-вычислений и фоновой аналитики. Подробнее о ней можно узнать в статье Workload Manager — управление потреблением ресурсов.